Bausteine einer Progressive Webapp
Was ist eine Progressive Webapp?
Eine Progressive Webapp verspricht in erster Linie ein deutlich
verbessertes mobiles Nutzererlebnis.
Insbesondere wird dies durch zwei Web-APIs unterstützt:
Pushmessages und
Offline-Speicherung. Aber
Progressive bedeutet z.B. auch
die Möglichkeit zu haben einen Button auf dem Homescreen
zu platzieren.
Die jeweilige Nutzung der Web-APIs aus der Webapplikation ist
stark vom eingesetzen Browser abhängig. Hierzu bietet die
Webseite
https://whatwebcando.today/ die Möglichkeit alle Web-API
und deren Verfügbarkeit zu prüfen bzw. auch zu testen.
Dezent im Hintergrund: Der Serviceworker
Die o.g. Kernmerkmale einer Progressive Weabpp benötigen einen
Mechanismus der im Hintergrund die Kommunikation mit der Umgebung
filtert und verantwortet. Hier kommt ein
Serviceworker zum Einsatz; dies ist ein eigenständiger
Prozess der auch bei geschlossenem Browser Empfang und Anzeige
einer z.B. Pushmessage übernimmt oder Request aus der Webanwendung
heraus filtern kann, z.B. für Offlineanwendungen.
https://serviceworke.rs
bietet gute Recipes für unterschiedliche Einsatzzwecke.
Wie genau funktionieren Pushmessages?
Hier eine Kurzanleitung:
- Serviceworker
- Wie oben beschrieben ist die Instanzierung eines
Serviceworkers die Grundvorraussetzung
- User für Pushmessage anmelden
- Die Applikation holt über den Browser die Einwilligung
des Nutzers für den Empfang von Nachrichten.
- Erzeugen eines Private/Public Schlüsselpaar
- Zur Kommunikation mit dem Pushservice muss ein
Schlüsselpaar erzeugt werden.
- Handshake mit Pushservice
- Der Pushservice wird vom Browser bestimmt, d.h. jeder
Browser hat einen festen Pushservice der nicht
änderbar ist(!). Hierfür wird dem Pushservice der öffentliche
Schlüssel bekanntgegeben, dieser dient später zur Zuordnung
von Browser und Nachricht.
- Versand einer Pushmessage
- Der Header einer Nachricht muss mit den privaten
Schlüssel signiert werden und beim Pushservice eingeliefert.
Pushmessages sind leider derzeit noch nicht in vielen
Browsern verfügbar, eine Ausnahme bildet hierbei
Chrome for Android.
Detaillierte Guides zu Pushmessages
https://web-push-book.gauntface.com
ist eine sehr detaillierte Anleitung, nutzbar auch als Cookbook.
https://pwa.rocks biete einige gute reale Referenzen, z.B. Ali Express.
05.08.2007
Dokumente (Bilder, Texte, Musik, …) als einzelne
Informationsobjekte sind nach wie vor das beherschende Medium in
der Zusammenarbeit von verteilten Teams. Allerdings sind diese
Objekte nur innerhalb einer definierten Systemgrenze (meist die des
eigenen Desktops) mit Metadaten angereichert die z.B. über die
Aktivität eines Dokumentes aufschluss gibt. Beim Verlassen dieser
Systemgrenze (z.B. via E-Mail) besitzt ein Dokument (wenn
überhaupt) nur noch rudimentäre Information über die eigene
Geschichte. Informationen über Orte, Personen oder
Aktivitätskennzahlen (z.B. Lese- und Schreibzugriffe) verbleiben
auf dem Quellsystem und sind für Dritte nicht mehr zugänglich. Die
Veröffentlichung Distributed Document Contexts in Cooperation
Systems beschreibt einen Ansatz diese Metainformationen (als Quelle
für einen Dokumenten-Kontext) über Systemgrenzen hinweg zu erhalten
und auf Basis vordefinierter Regeln verschiedene Kennzahlen eines
Dokumenten-Kontextes bereitzustellen. Das o.g. Paper beschreibt
hierbei in erster Linie die Relation von Nutzern zu einem Dokument.
Hierbei wird das sog. Involvement eines Nutzers zu einem Dokument
über einen gewissen Zeitraum beschrieben.
Referenz: Vonrueden, M.; Prinz, W.: Distributed
Document Contexts in Cooperation Systems. In: B. Kokinov et al.
(Eds.) CONTEXT 2007, LNAI vol. 4635, pp. 507-512, Springer-Verlag
Berlin Heidelberg 2007
11.05.2007
In einem Showcase
für das Social-Networking innerhalb eines Unternehmens wurde
gezeigt, wie die Interaktion zwischen AutoID-Verfahren wie z.B.
RFID und sozialen Netzwerken aussehen kann. In diesem Showcase
wurde auf Basis einer persönlichen RFID-Karte das derzeitige
soziale Netzwerk einer Person innerhalb des Unternehmens in einer
Graphenvisualisierung generiert. Dieser navigierbare Graph zeigte
die jeweiligen Mitarbeiter und Kollegen der Person an, die über
die gleichen bzw. ähnliche Eigenschaften verfügten. Zur
Akzentuierung wurden grafische Mittel wie Linenstärke benutzt, um
starke und schwächere Verbindungen zu visualisieren.
Eine weitere Ausprägung dieses Showcases, war ebenfalls die
Visualisierung der Standorte der jeweiligen Mitarbeiter via
Google-Earth. Als weltweit aggierendes Unternehmen zeigte sich
hier, wo die geographischen Hotspots aus Unternehmensischt liegen.
Die Interaktion des Showcases beruhte ebenfalls auf Basis der
RFID-Karte, wobei nach Einlesen der eindeutigen ID der jewelige
Standort des Mitarbeiters in Google-Earth “angeflogen” wurde.
Eine weitere Zusammenfassung dieses Showcases findet sich im
Context der CSCW-Konferenz 2008 http://www.cscw2008.org bzw.
direkt als PDF-Version. Auf den Seiten des Fraunhofer Instituts
FIT befindet sich ein Kurzvorstellung aller in diesem Rahmen
erstellten Showcases.
Eingesetzte Tools und Frameworks für diesen Showcase:
16.07.2005
Wissen ist eine der zentralen Säulen der heutigen Gesellschaft. Neue Techniken, Wissen auch maschinell fassbar zu machen deuten an, welche strategische Bedeutung dem Wissensbegriff zukommt. Im Kontext des Semantic Webs ist oft die Rede von der Ontologie als Struktur zur Darstellung und Speicherung von Semantik und Wissen. Losgelöst von der maschinellen Interpretation, analysiert diese Arbeit den Einsatz von Ontologien zur Strukturierung von Wissen in einer Mensch-Mensch Relation. Da die Wissensgewinnung nicht als singulärer sondern als gemeinschaftlicher Prozess anzusehen ist, wird der Fokus hier insbesondere auf eine kooperative Erstellung von Ontologien gelegt. Dieser Fokus gliedert sich in einen konzeptionellen und anwendungsorientierten Bereich.
Konzeptionell werden drei verschiedene Aspekte erörtert. Neben einer Einordnung von Ontologien als Wissensstruktur und der Notwendigkeit einer kooperativen Bearbeitung wird der eigentliche Prozess des Aufbaus von Ontologien ebenso beschrieben, wie eine generelle Vorgehensweise zur Visualisierung dieser Struktur. Während für die grafische Darstellung des ontologischen Konzepts mögliche Herangehensweisen abgewogen werden, geht die Beschreibung des Aufbauprozesses auf Probleme und Notwendigkeiten einer kooperativ gestützten Wissenserarbeitung ein. Besondere Kernelemente bilden hier die Findung eines Konsenses, die gegenseitige Wahrnehmung und das Nachvollziehen des Wissensprozesses.
Neben dem Entwurf möglicher Einsatz-Szenarien wird eine entwickelte Anwendung zum kooperativen Aufbau einer Ontologie vorgestellt. Basierend auf dem aufgestellten Konzept wird eine Nutzer-Applikation beschrieben, die mit Hilfe einer grafischen Metapher die ontologische Struktur visualisiert. Als generelle und organisatorische Komponente für die Handhabung von Ontologien wird abschließend ein Server-Modul für die openSteam-Umgebung präsentiert.
Vollständige Diplomarbeit
Die komplette Diplomarbeit ist als pdf-Datei [4,6MB] verfügbar. Bitte zögern Sie nicht mit einem Feedback.
Veröffentlichungen zur Diplomarbeit
- Vonrueden, M.; Hampel, T.: Collaborative Ontologies and Its Visualisation in CSCW Systems. In: Chen, Chi- Sheng; Filipe, Joaquim; Seruca, Isabel; Cordeiro, José (Hrsg.): Proceedings of the 7th International Conference On Enterprise Information Systems (ICEIS 2005) Bd. 3 INSTICC, 2005, S. 294-299
siehe auch Artikel-Verzeichnis ICEIS 2005
- Vonrueden, M., Hampel, T.: Collaborative Ontologies in Knowledge Management. In: Piet Kommers, Griff Richards (eds.): Proceedings of Ed-Media – World Conference on Educational Multimedia, Hypermedia & Telecommunications, Montréal, Canada, June 27 – July 2, 2005, 2145-2152.
siehe auch: AACE/ED-MEDIA 2005.
Präsentation der Diplomarbeit
Für einen schnellen Überblick ist nachstehend die Präsentation als PDF verfügbar.
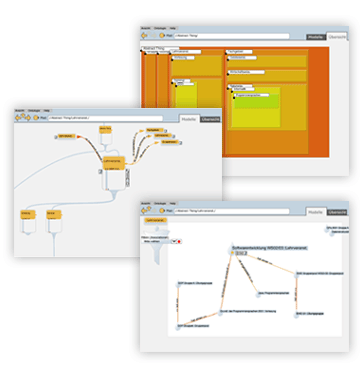
Die Anwendung “visCOntE”
Zu sehen sind hier die drei Ansichten einer Ontologie innerhalb des webbasierten Clients. Nachfolgend erhalten Sie Gelegenheit eine Ontologie zu explorieren und auch zu ändern.  Für die Betrachtung einer Beispielontologie mit Hilfer der grafischen Anwendung (visCOntE) benötigen Sie das SVG-Plugin von Adobe in der Version 3. Ferner benötigen Sie einen Login für das openSteam-System, den Sie hier bekommen können. ein.Alternativ können Sie sich auch einen 94 Sekunden Film (4,4MB, Mpeg4) über die vielfältigen Möglichkeiten der Exploration einer Ontologie mit Hilfe von “visCOntE”- visual Cooperative Ontology Environment ansehen.
Für die Betrachtung einer Beispielontologie mit Hilfer der grafischen Anwendung (visCOntE) benötigen Sie das SVG-Plugin von Adobe in der Version 3. Ferner benötigen Sie einen Login für das openSteam-System, den Sie hier bekommen können. ein.Alternativ können Sie sich auch einen 94 Sekunden Film (4,4MB, Mpeg4) über die vielfältigen Möglichkeiten der Exploration einer Ontologie mit Hilfe von “visCOntE”- visual Cooperative Ontology Environment ansehen.
Weiteres…
Weitere Informationen zu Wissensräumen, kooperative Systeme und openSteam erhalten Sie auf den Seiten des Lehrstuhles IUG.
20.06.2005
Ein Panel-Applet für die KDE Oberfläche des Linux-Betriebssystems. Mit diesem kleinen Werkzeug ist es möglich aus allen Anwendungen, den mit der Maus selektierten Text an einen Webdienst wie z.B. Google, Leo Dictionary oder auch Wikipedia zu übermitteln. Hieraus ergibt sich eine übergeifende Nachschlagestruktur für eine schnelle Informationsabfrage.
Beschreibung
KlipOQuery ist ein Panelapplet für die KDE-Desktopoberfläche (Linux). Dieses Applet verbindet kopierten Textelement aus dem Klipper (Zwischenablage) und einem spezifiezierten Web-Dienst wie z.B. Google oder das Englisch-Deutsch Wörterbuch Leo. Hier nun eine kleine Beschreibung wie das Tool generell funktioniert bzw. wie eine Übermittlung an einen Webdienst abläuft:
- Der User selektiert einen Text in einer beliebigen Applikation.
- Damit wird dieser Text automatisch in das Klipper – Menü von KDE kopiert
- Der Nutzer kann jetzt entweder direkt auf den Button von KlipOQuery in der Taskleiste drücken oder einen neuen Dienst in dem KlipoQuery Menü auswählen (rechter mousebutton).
- Daraufhin wird der selektierte Text in die URL kopiert und der Standard-Webrowser gestartet, der die jeweilige URL (also die direkte Webseite) aufruft.
Downloads
Das aktuelle KlipOQuery-Source Paket:
Extra Konfigurationsdateien: Deutsprachige Dienste:
Distributions-spezifische Pakete:
Changelog
siehe Changelog
Screenshots



Hilfe
Übersetzung des Quellpaketes:
Standard:
./configure (default prefix ist /usr/kde/3.3)
make
make install
Kubuntu:
KDE_DIR=/usr/lib/kde3/
./configure –prefix=$KDE_DIR
make
make install
ln -s $KDE_DIR/lib/libklipoquery.so /usr/lib/kde3/libklipoquery.so
ln -s $KDE_DIR/lib/libklipoquery.la /usr/lib/kde3/libklipoquery.la
ln -s $KDE_DIR/share/apps/kicker/applets/klipoquery.desktop /usr/share/apps/kicker/applets/klipoquery.desktop
Installation des Gentoo Ebuild:
- Für eine dauerhafte Speicherung im Portage bzw. nach einem emerge sync Kommando, sollte ein extra portage layer in /etc/make.conf (z.B. PORTDIR_OVERLAY=/usr/local/portage) aufgenommen werden
- Das Ebuild in das standard /usr/portage/app-misc/ bzw. eigene Portage Verzeichnis kopieren
- (Optional) Das Quellpaket [KlipOQuery v0.2.4] in das /usr/portage/distfiles Verzeichnis kopieren
- Mit dem Kommando emerge -[p]v klipoquery installieren
Zum Dock hinzufügen
KDE-Session neu starten, dann Rechter Mausklick in das Dock, Hinzufügen wählen, dann Menü Miniprogramme und letztlich klipoquery auswählen.
Webdienst hinzufügen
Im Eigenschaften Dialog sind die vorhandenen Webdienste in einer Baum- bzw. Gruppenstruktur abgebildet. An dieser Stelle kann ein neuer Dienst hinzugefügt werden. Wie das geht ist hier beschrieben:
- Als Beispiel soll an dieser Stelle der Webdienst dict.leo.org dienen. Nach einem Aufruf der Website und der Übersetzung des Wortes John Doe. zeigt sich folgende URL in der Adressleiste des Browsers:http://dict.leo.org/?John%20Doe
- Um diesen Dienst in KlipoQuery nutzen zu können, muss diese Adresse kopiert und eingesetzt werden und der Ausdruck John%20Doe mit dem Ausdruck %s ersetzt werden. Die Url im Eigenschaften Dialog sollte nun folgendermaßen aussehen: http://dict.leo.org/?%s
- Nun noch einen Namen vergeben und speichern. Fertig
Verschiedenes
- Dienste können in frei definierbare Gruppen unterteilt werden
- Aktivierung und Deaktivierung von Diensten
- Top[1-10] zeigt die am häufigsten genutzten Dienste
Dank auch an…
an alle für die Unterstützung in Bezug auf Installationstips, RPM-Packaging und Promotion!
02.02.02
Eine Übungsaufgabe innerhalb der Vorlesung Computergrafik 1. Implementierung einer drei-dimensionalen Darstellung eines Karussels, basierend auf einem Java-Applet.
Mit der Themenstellung “Jahrmarkt”wurde abschließend zu der Veranstaltung “Computergrafik 1″ die Aufgabe gestellt, mit Hilfe von openGL Befehlen eine drei dimensionale Darstellung eines Karussels zu implementieren. Mit Fokus auf die Repräsentation innerhalb eines Webbrowsers sollte ein Java-Applet mit Hilfe der openGL-Bibliothek gl4java. erstellt werden.
Das hier gezeigte Beispiel zeigt eine Schiffschaukel auf einem Planeten. Von Interesse ist auch die Klasse WaveFrontParser.java, mit deren Hifle exportierte *.obj Datein aus Alias Wavefronts Maya in openGL Koordinaten transformiert werden können.
Für die Betrachtung dieser Animation ist eine Installation der openGL- Bibliothek gl4java nötig. Hilfestellungen und andere Beispiele finden sie unter





